Implementing Software
Network architectures and protocol specifications are essential things, but a good blueprint is not enough to explain the phenomenal success of the Internet: The number of computers connected to the Internet has been doubling every year since 1981 and is now approaching the impressive number of 1,966,514,816; It is believed that the number of bits transmitted over the Internet surpassed the corresponding figure for the voice phone system sometime in 2001.What explains the success of the Internet?
- There are certainly many contributing factors (including a good architecture), but
- one thing that has made the Internet such a runaway success is the fact that so much of its functionality is provided by software running in general-purpose computers. The significance of this is that new functionality can be added readily with “just a small matter of programming.” As a result, new applications and services—electronic commerce, videoconferencing, and packet telephony, to name a few—have been showing up at a phenomenal pace.
- A related factor is the massive increase in computing power available in commodity machines. Although computer networks have always been capable in principle of transporting any kind of information, such as digital voice samples, digitized images, and so on, this potential was not particularly interesting if the computers sending and receiving that data were too slow to do anything useful with the information. Virtually all of today’s computers are capable of playing back digitized voice at full speed and can display video at a speed and resolution that is useful for some (but by no means all) applications. Thus, today’s networks have begun to support multimedia, and their support for it will only improve as computing hardware becomes faster.
In many respects, network applications and network protocols are very similar—the way an application engages the services of the network is pretty much the same as the way a high-level protocol invokes the services of a low-level protocol. As we will see later in the section, however, there are a couple of important differences.
Application Programming Interface (Sockets)
The place to start when implementing a network application is the interface exported by the network.
Since most network protocols are implemented in software (especially those high in the protocol stack), and nearly all computer systems implement their network protocols as part of the operating system, when we refer to the interface “exported by the network,” we are generally referring to the interface that the OS provides to its networking subsystem. This interface is often called the networkAlthough each operating system is free to define its own network API (and most
application programming interface (API).
have), over time certain of these APIs have become widely supported; that is, they
have been ported to operating systems other than their native system. This is what has happened with the socket interface originally provided by the Berkeley distribution of Unix, which is now supported in virtually all popular operating systems.
The advantage of industry-wide support for a single API is that applications can be easily ported from one OS to another.It is important to keep in mind, however, that application programs typically interact with many parts of the OS other than the network; for example, they read and write files, fork concurrent processes, and output to the graphical display. Just because two systems support the same network API does not mean that their file system, process, or graphic interfaces are the same. Still, understanding a widely adopted API like Unix sockets gives us a good place to start.
Before describing the socket interface, it is important to keep two concerns separate in your mind.
- Each protocol provides a certain set of services, and
- the API provides a syntax by which those services can be invoked in this particular OS.
- The implementation is then responsible for mapping the tangible set of operations and objects defined by the API onto the abstract set of services defined by the protocol.
- If you have done a good job of defining the interface, then it will be possible to use the syntax of the interface to invoke the services of many different protocols.
- Such generality was certainly a goal of the socket interface, although it’s far from perfect.
- creating a socket,
- attaching the socket to the network,
- sending/receiving messages through the socket, and
- closing the socket.
int socket(int domain, int type, int protocol)
The reason that this operation takes three arguments is that the socket interface was designed to be general enough to support any underlying protocol suite. Specifically,
- the domain argument specifies the protocol family that is going to be used:
- PF INET denotes the Internet family,
- PF UNIX denotes the Unix pipe facility, and
- PF PACKET denotes direct access to the network interface (i.e., it bypasses the TCP/IP protocol stack).
- The type argument indicates the semantics of the communication.
- SOCK STREAM is used to denote a byte stream.
- SOCK DGRAM is an alternative that denotes a message-oriented service, such as that provided by UDP.
- The protocol argument identifies the specific protocol that is going to be used.
- In our case, this argument is UNSPEC because the combination of PF INET and SOCK STREAM implies TCP.
- Finally, the return value from socket is a handle for the newly created socket, that is, an identifier by which we can refer to the socket in the future.
- It is given as an argument to subsequent operations on this socket.
int bind(int socket, struct sockaddr *address, int addr len) int listen(int socket, int backlog) int accept(int socket, struct sockaddr *address, int *addr len)
The bind operation, as its name suggests, binds the newly created socket to the specified address. This is the network address of the local participant—the server.
Note that, when used with the Internet protocols, address is a data structure that includes both the IP address of the server and a TCP port number. (As we know ports are used to indirectly identify processes. They are a form of demux keys as defined in an earlier post)The port number is usually some well-known number specific to the service being offered; for example, Web servers commonly accept connections on port 80.
The listen operation then defines how many connections can be pending on the specified socket. Finally, the accept operation carries out the passive open.
It is a blocking operation that does not return until a remote participant has established a connection, and when it does complete, it returns a new socket that corresponds to this just-established connection, and the address argument contains the remote participant’s address.
Note that when accept returns, the original socket that was given as an argument still exists and still corresponds to the passive open; it is used in future invocations of accept.On the client machine, the application process performs an active open; that is, it says who it wants to communicate with by invoking the following single operation:
int connect(int socket, struct sockaddr *address, int addr len)
This operation does not return until TCP has successfully established a connection, at which time the application is free to begin sending data. In this case, address contains the remote participant’s address. In practice, the client usually specifies only the remote participant’s address and lets the system fill in the local information.
Whereas a server usually listens for messages on a well-known port, a client typically does not care which port it uses for itself; the OS simply selects an unused one.Once a connection is established, the application processes invoke the following two operations to send and receive data:
int send(int socket, char *message, int msg len, int flags) int recv(int socket, char *buffer, int buf len, int flags)
The first operation sends the given message over the specified socket, while the second operation receives a message from the specified socket into the given buffer. Both operations take a set of flags that control certain details of the operation.
Example Application
We now show the implementation of a simple client/server program that uses the socket interface to send messages over a TCP connection. The program also uses other Unix networking utilities, which we introduce as we go. Our application allows a user on one machine to type in and send text to a user on another machine. It is a simplified version of the Unix talk program, which is similar to the program at the core of a Web chat room.
Client
We start with the client side, which takes the name of the remote machine as an argument.
- It calls the Unix utility gethostbyname to translate this name into the remote host’s IP address.
- The next step is to construct the address data structure (sin) expected by the socket interface. Notice that this data structure specifies that we’ll be using the socket to connect to the Internet (AF INET). In our example, we use TCP port 5432 as the well-known server port; this happens to be a port that has not been assigned to any other Internet service.
- The final step in setting up the connection is to call socket and connect. Once the connect operation returns, the connection is established and the client program enters its main loop, which reads text from standard input and sends it over the socket.
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#define SERVER_PORT 5432
#define MAX_LINE 256
int main(int argc, char * argv[])
{
FILE *fp;
struct hostent *hp;
struct sockaddr_in sin;
char *host;
char buf[MAX_LINE];
int s;
int len;
if (argc==2) {
host = argv[1];
}
else {
fprintf(stderr, "usage: simplex-talk host\n");
exit(1);
}
/* translate host name into peer's IP address */
hp = gethostbyname(host);
if (!hp) {
fprintf(stderr, "simplex-talk: unknown host: %s\n", host);
exit(1);
}
/* build address data structure */
bzero((char *)&sin, sizeof(sin));
sin.sin_family = AF_INET;
bcopy(hp->h_addr, (char *)&sin.sin_addr, hp->h_length);
sin.sin_port = htons(SERVER_PORT);
/* active open */
if ((s = socket(PF_INET, SOCK_STREAM, 0)) < 0) {
perror("simplex-talk: socket");
exit(1);
}
if (connect(s, (struct sockaddr *)&sin, sizeof(sin)) < 0) {
perror("simplex-talk: connect");
close(s);
exit(1);
}
/* main loop: get and send lines of text */
while (fgets(buf, sizeof(buf), stdin)) {
buf[MAX_LINE-1] = '\0';
len = strlen(buf) + 1;
send(s, buf, len, 0);
}
}Server The server is equally simple.
- It first constructs the address data structure by filling in its own port number (SERVER PORT). By not specifying an IP address, the application program is willing to accept connections on any of the local host’s IP addresses.
- Next, the server performs the preliminary steps involved in a passive open:
- creates the socket,
- binds it to the local address, and
- sets the maximum number of pending connections to be allowed.
- Finally, the main loop waits for a remote host to try to connect, and
- when one does, receives and prints out the characters that arrive on the connection.
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#define SERVER_PORT 5432
#define MAX_PENDING 5
#define MAX_LINE 256
int main()
{
struct sockaddr_in sin;
char buf[MAX_LINE];
int len;
int s, new_s;
/* build address data structure */
bzero((char *)&sin, sizeof(sin));
sin.sin_family = AF_INET;
sin.sin_addr.s_addr = INADDR_ANY;
sin.sin_port = htons(SERVER_PORT);
/* setup passive open */
if ((s = socket(PF_INET, SOCK_STREAM, 0)) < 0) {
perror("simplex-talk: socket");
exit(1);
}
if ((bind(s, (struct sockaddr *)&sin, sizeof(sin))) < 0) {
perror("simplex-talk: bind");
exit(1);
}
listen(s, MAX_PENDING);
/* wait for connection, then receive and print text */
while(1) {
if ((new_s = accept(s, (struct sockaddr *)&sin, &len)) < 0){
perror("simplex-talk: accept");
exit(1);
}
while (len = recv(new_s, buf, sizeof(buf), 0))
fputs(buf, stdout);
close(new_s);
}
}Protocol Implementation Issues
As mentioned at the beginning of this section, the way application programs interact with the underlying network is similar to the way a high-level protocol interacts with a low-level protocol. For example, TCP needs an interface to send outgoing messages to IP, and IP needs to be able to deliver incoming messages to TCP. This is exactly the service interface introduced in an earlier post.
Since we already have a network API (e.g., sockets), we might be tempted to use this same interface between every pair of protocols in the protocol stack. Although certainly an option, in practice the socket interface is not used in this way.
The reason is that there are inefficiencies built into the socket interface that protocol implementers are not willing to tolerate. Application programmers tolerate them because they simplify their programming task and because the inefficiency only has to be tolerated once, but protocol implementers are often obsessed with performance and must worry about getting a message through several layers of protocols.The rest of this section discusses the two primary differences between the network API and the protocol-to-protocol interface found lower in the protocol graph.
Process Model
Most operating systems provide an abstraction called a process, or alternatively, a thread.
Each process runs largely independently of other processes, and the OS is responsible for making sure that resources, such as address space and CPU cycles, are allocated to all the current processes. The process abstraction makes it fairly straightforward to have a lot of things executing concurrently on one machine;for example, each user application might execute in its own process, and various things inside the OS might execute as other processes. When the OS stops one process from executing on the CPU and starts up another one, we call the change a context switch.

When designing the network subsystem, one of the first questions to answer is, “Where are the processes?” There are essentially two choices, as illustrated in Figure 1.16.
- In the first, which we call the process-per-protocol model, each protocol is implemented by a separate process. This means that as a message moves up or down the protocol stack, it is passed from one process/protocol to another—the process that implements protocol i processes the message, then passes it to protocol i − 1, and so on.
- How one process/protocol passes a message to the next process/protocol depends on the support the host OS provides for interprocess communication.
- Typically, there is a simple mechanism for enqueuing a message with a process. The important point, however, is that a context switch is required at each level of the protocol graph—typically a time-consuming operation.
- The alternative, which we call the process-per-message model, treats each protocol as a static piece of code and associates the processes with the messages.
- That is, when a message arrives from the network, the OS dispatches a process that it makes responsible for the message as it moves up the protocol graph.
- At each level, the procedure that implements that protocol is invoked, which eventually results in the procedure for the next protocol being invoked, and so on.
- For outbound messages, the application’s process invokes the necessary procedure calls until the message is delivered.
Although the process-per-protocol model is sometimes easier to think about—I implement my protocol in my process, and you implement your protocol in your process—the process-per-message model is generally more efficient for a simple reason: A procedure call is an order of magnitude more efficient than a context switch on most computers. The former model requires the expense of a context switch at each level,while the latter model costs only a procedure call per level.
Now think about the relationship between the service interface as defined above and the process model.
- For an outgoing message, the high-level protocol invokes a send operation on the low-level protocol. Because the high-level protocol has the message in hand when it calls send, this operation can be easily implemented as a procedure call; no context switch is required.
- For incoming messages, however, the high-level protocol invokes the receive operation on the low-level protocol, and then must wait for a message to arrive at some unknown future time; this basically forces a context switch.
- In other words, the process running in the high-level protocol receives a message from the process running in the low-level protocol. This isn’t a big deal if only the application process receives messages from the network subsystem—in fact, it’s the right interface for the network API since application programs already have a process-centric view of the world—but it does have a significant impact on performance if such a context switch occurs at each layer of the protocol stack. It is for this reason that most protocol implementations replace the receive operation with a deliver operation. That is, the low-level protocol does an upcall—a procedure call up the protocol stack—to deliver the message to the high-level protocol.

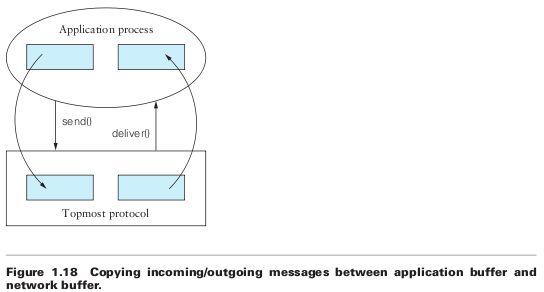
Message Buffers
A second inefficiency of the socket interface is that the application process provides the buffer that contains the outbound message when calling send, and similarly it provides the buffer into which an incoming message is copied when invoking the receive operation. This forces the topmost protocol to copy the message from the application’s buffer into a network buffer, and vice versa, as shown in Figure 1.18.
It turns out that copying data from one buffer to another is one of the most expensive things a protocol implementation can do. This is because while processors are becoming faster at an incredible pace, memory is not getting faster as quickly as processors are.

Finally i found of implementing software information. i need it because of i am going to implement of e-cart website so that i need above all content as welll as logic.Thanks a lot...
ReplyDelete----------
Computer Networking Los Angeles